Building a simple SMILES based QSAR model with LSTM cells in PyTorch
Last blog-post I showed how to use PyTorch to build a feed forward neural network model for molecular property prediction (QSAR: Quantitative structure-activity relationship). RDKit was used to fingerprint the molecule and the fingerprints was used as numeric representations for the neural network. But what if the fingerprint is not the best representation to use for this particular task we are modelling? We could start a search for better features, other fingerprint algorithms, calculated descriptors or engineer our own. An alternative to searching for representations is to use deep learning, where we, popularly speaking, let the network figure our it’s own way to extract the features that are best suited for the task we want the model to perform. This has shown some great results within other domains such as image recognition and natural language processing. It do often require a lot of data, but if the complexity of the models are kept down and over-fitting is counteracted with regularization and other tricks, it can sometimes also work for smaller datasets. I’ve previously worked with LSTM based models, which directly reads-in the molecules as SMILES strings and build QSAR models or translators, but I have not shown how this can be done with PyTorch. So read on below, if you want to see an example of how this can be done with PyTorch.
First some imports:
import numpy as np import pandas as pd import matplotlib.pyplot as plt from rdkit import Chem, DataStructs from rdkit.Chem import PandasTools, AllChem from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split import torch import torch.nn as nn from torch.utils.data import Dataset from torch.optim.lr_scheduler import ReduceLROnPlateau
The same dataset ExcapeDB that was used in the previous Blog-post will again be used as a test-case.
data = pd.read_csv("SLC6A4_active_excape_export.csv")
data.head(1)
| Ambit_InchiKey | Original_Entry_ID | Entrez_ID | Activity_Flag | pXC50 | DB | Original_Assay_ID | Tax_ID | Gene_Symbol | Ortholog_Group | SMILES | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | DFPSUOZWGQDKPI-COPLHBTANA-N | 45380180 | 6532 | A | 8.40012 | pubchem | 462683 | 9606 | SLC6A4 | 4061 | ClC=1C=C([C@]23[C@H]([C@@H]2CN(C)C)CNC3)C=CC1Cl |
RDKit will be used as the molecular format for MolVecGen, a package for SMILES based vectorization of molecules and we’ll start by converting the SMILES to RDKit molecular objects. The pandastools module contain a convenient function for creating a molecule column, that also makes the column work with nicely with Jupyterlab and notebooks. The Molecule column is rendered when displayed in the notebook, which can give an easier overview.
PandasTools.AddMoleculeColumnToFrame(data,'SMILES','Molecule') data[["SMILES","Molecule"]].head(1)
| SMILES | Molecule | |
|---|---|---|
| 0 | ClC=1C=C([C@]23[C@H]([C@@H]2CN(C)C)CNC3)C=CC1Cl |  |
As just mentioned above, I’ll use the MolVecGen package to vectorize the SMILES. The package was originally written to work with Keras generators during training. However, generators can no longer be used in Keras, but the vectorization class that converts SMILES into one-hot encoded tensors can easily be adapted to work with PyTorch. The package can be used after cloning the github repository and installed with “python setup.py install” in your Python environment (e.g. Conda or virtualenv).
Vectorizing the SMILES with data augmentation
from molvecgen.vectorizers import SmilesVectorizer
The object is initialized with the generation parameters and subsequently fitted to the dataset. This analyzes the dataset for what characters it contains and the maximal length. As the augmentation can result in longer SMILES strings as well as the appearance of some additional characters, some extra padding and characters may be needed to avoid too many “?” which are unknown characters. It doesn’t appear to be a huge issue for this dataset.
smivec = SmilesVectorizer(pad=1, leftpad=True, canonical=False, augment=True) smivec.fit(data.Molecule.values, )
After fitting we can inspect the charachter set and the dimensions of the produced one-hot encoded SMILES including the padding
print(smivec.charset) smivec.dims
@sH=32NBF]-+oCO5n\l46[Ir71#c8/)S(^$?
(127, 36)
Before we start to manipulate the dataset with normalization it’s important to split into train, validation (development) and test sets. Scikit-learn, contains some convenient functions to split into different sets as well as normalize the target values.
y = data.pXC50.values.reshape((-1,1)) X = data.Molecule.values X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.10, random_state=42) X_train, X_validation, y_train, y_validation = train_test_split(X_train, y_train, test_size=0.05, random_state=42) #Normalizing output using standard scaling scaler = StandardScaler() y_train = scaler.fit_transform(y_train) y_test = scaler.transform(y_test) y_validation = scaler.transform(y_validation)
PyTorch works with datasets, and we can easily integrate the vectorizer by subclassing the __getitem__ method and the __len__method. This way we can load the dataset with RDKit molecular objects and generate the tensors on the fly. This allows us to use SMILES augmentation on the fly without pre vectorizing the dataset. This is a small overhead during training, but it is convenient and allows to handle huge datasets without running out of memory.
Wrapping the SMILES vectorizer in a PyTorch dataset
class SMILESMolDataset(Dataset):
def __init__(self, molecules, y, vectorizer):
self.molecules = molecules
self.y = y
self.vectorizer = vectorizer
def __len__(self):
return len(self.molecules)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
mols = self.molecules[idx]
#The vectorizer was written to work with batches,
#but PyTorch datasets unfortunately works with single samples
sample = self.vectorizer.transform([mols])[0]
label = self.y[idx]
return sample, label
Now we can create and work with the dataset. Calling the first items returns the vector and the target value. Calling it again will most probably result in a different augmented SMILES tensor as we turned on augmentation.
train_dataset = SMILESMolDataset(X_train, y_train, smivec) train_dataset[0]
(array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 1, 0]], dtype=int8), array([1.11689878]))
The validation set will be calculated and kept fixed, it’s merely used to monitor for potential overfitting. Let’s get those arrays transfered to the GPU memory as tensors. If you don’t have a GPU, buy a graphics card. I have for a long time used a 1060 GTX, which is not that expensive anymore. Alternatively, Google colab give access to an interactive notebook with a GPU for free, which is an inexpensive way to get started and experimenting.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
X_validation_t = smivec.transform(X_validation, canonical=False)
X_validation_t = torch.tensor(X_validation_t, device=device).float()
y_validation_t = torch.tensor(y_validation, device=device).float()
X_validation_t.shape
cuda:0
torch.Size([326, 127, 36])
Defining the PyTorch LSTM molecular model
Having the datasets and preprocessing in place it’s time for the fun part. Defining the neural network architecture. I’ve kept this really simple with just a single layer of LSTM cells and a bit of dropout for conteracting over-fitting.
class Net(nn.Module):
def __init__(self, dimensions, lstm_size, hidden_size, dropout_rate, out_size):
super(Net, self).__init__()
length = dims[0]
number_tokens = dims[1]
self.lstm = nn.LSTM(input_size=number_tokens, hidden_size=lstm_size, num_layers=1, batch_first=True, bidirectional=False)
self.fc1 = nn.Linear(lstm_size, hidden_size) # Output layer
self.activation = nn.ReLU() # Non-Linear ReLU Layer
self.fc_out = nn.Linear(hidden_size, out_size) # Output layer
self.dropout = nn.Dropout(dropout_rate)
def forward(self, x):# Forward pass: stacking each layer together
out, (h_n, c_n) = self.lstm(x) #LSTM network reads in one-hot-encoded SMILES, h_n is last output, out is for all timesteps
out = self.dropout(h_n) #Dropout
out = self.fc1(out) # Pass into the hidden layer
out = self.activation(out) # Use ReLU on hidden activation
out = self.dropout(out) # dropout
out = self.fc_out(out) # Use a linear layer for the output
return out
Lets define some parameters that will control the size and dropout of the network. These ideally needs to be tuned with some algorithm, but here I simply choose some parameters based on a bit of experimenting.
epochs = 750 dims = smivec.dims lstm_size = 128 # The size of the LSTM layer hidden_size = 128 # The size of the hidden non-linear layer dropout_rate = 0.50 # The dropout rate output_size = 1 # This is just a single task, so this will be one batch_size = 128 # The mini_batch size during training learning_rate = 0.003 # The initial learning rate for the optimizer
model = Net(smivec, lstm_size, hidden_size, dropout_rate, output_size) model.cuda()
Net(
(lstm): LSTM(36, 128, batch_first=True)
(fc1): Linear(in_features=128, out_features=128, bias=True)
(activation): ReLU()
(fc_out): Linear(in_features=128, out_features=1, bias=True)
(dropout): Dropout(p=0.5, inplace=False)
)
A quick test to see that the network is working is to predict a sample from the validation set, as this is already vectorized. The output will probably not be right, but it will show that the networks tensors are at least not having technical errors in the way they are connected
pred = model.forward(X_validation_t[10:11]) pred
tensor([[[-0.0323]]], device='cuda:0', grad_fn=)
Mean square error is a reasonable loss function for regression tasks, and Adam will be used to optimize the weights. A learning rate scheduler will lower the loss once the validation loss stops to improve.
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
lr_scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=50,
verbose=True, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=1e-6, eps=1e-08)
The train dataset will be used together with a PyTorch dataloader to provide randomly selected mini-batches for the training.
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True, num_workers=4)
A quick test of the train_loader which also provides us with some samples to work if needed for trouble shooting.
for smiles, labels in train_loader:
break
Training the PyTorch SMILES based LSTM model
Training is a bit more handheld than in keras. The one_hot encoded smiles are provided by the train_loader and moved to the gpu. The gradients of the optimizer are zeroed and the output calculated of the model. This also records the differentials needed for back propagation. The loss is calculated and passed backward which calculates the gradient with respect to the loss. The weights are then changed using the optimizer. At the end of each for loop the model is switched into evaluation mode (dropout layers inactivated), and some statistics calculated and printed.
model.train() #Ensure the network is in "train" mode with dropouts active
train_losses = []
validation_losses = []
for e in range(epochs):
running_loss = 0
for smiles, labels in train_loader:
# Push numpy to CUDA tensors
smiles = torch.tensor(smiles, device=device).float()
labels = torch.tensor(labels, device=device).float()
# Training pass
optimizer.zero_grad() # Initialize the gradients, which will be recorded during the forward pass
output = model(smiles) #Forward pass of the mini-batch
loss = criterion(output, labels) #Computing the loss
loss.backward() # calculate the backward pass
torch.nn.utils.clip_grad_norm_(model.parameters(), 1)
optimizer.step() # Optimize the weights
running_loss += loss.item()
else:
model.eval()
validation_loss = torch.mean(( y_validation_t - model(X_validation_t) )**2).item()
model.train()
lr_scheduler.step(validation_loss)
train_loss = running_loss/len(train_loader)
train_losses.append(train_loss)
validation_losses.append(validation_loss)
if (e+1)%10 == 0:
print("Epoch %i, Training loss: %0.2F Validation loss: %0.2F"%(e + 1, train_loss, validation_loss))
/home/esben/git/envs/ML/lib/python3.6/site-packages/ipykernel_launcher.py:10: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
# Remove the CWD from sys.path while we load stuff.
/home/esben/git/envs/ML/lib/python3.6/site-packages/ipykernel_launcher.py:11: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
# This is added back by InteractiveShellApp.init_path()
/home/esben/git/envs/ML/lib/python3.6/site-packages/torch/nn/modules/loss.py:431: UserWarning: Using a target size (torch.Size([128, 1])) that is different to the input size (torch.Size([1, 128, 1])). This will likely lead to incorrect results due to broadcasting. Please ensure they have the same size.
return F.mse_loss(input, target, reduction=self.reduction)
/home/esben/git/envs/ML/lib/python3.6/site-packages/torch/nn/modules/loss.py:431: UserWarning: Using a target size (torch.Size([35, 1])) that is different to the input size (torch.Size([1, 35, 1])). This will likely lead to incorrect results due to broadcasting. Please ensure they have the same size.
return F.mse_loss(input, target, reduction=self.reduction)
Epoch 10, Training loss: 0.86 Validation loss: 0.93
Epoch 20, Training loss: 0.77 Validation loss: 0.80
Epoch 30, Training loss: 0.73 Validation loss: 0.72
Epoch 40, Training loss: 0.64 Validation loss: 0.67
Epoch 50, Training loss: 0.61 Validation loss: 0.65
Epoch 60, Training loss: 0.57 Validation loss: 0.57
...
Epoch 670, Training loss: 0.19 Validation loss: 0.39
Epoch 680, Training loss: 0.19 Validation loss: 0.39
Epoch 690, Training loss: 0.19 Validation loss: 0.38
Epoch 700, Training loss: 0.19 Validation loss: 0.38
Epoch 703: reducing learning rate of group 0 to 4.6875e-05.
Epoch 710, Training loss: 0.19 Validation loss: 0.38
Epoch 720, Training loss: 0.19 Validation loss: 0.38
Epoch 730, Training loss: 0.19 Validation loss: 0.38
Epoch 740, Training loss: 0.19 Validation loss: 0.38
Epoch 750, Training loss: 0.19 Validation loss: 0.38
After training we can plot the training. It looks a little overfit as the validation loss is diverging and maybe rising a bit in the end. Changing the hyperparameters and retraining could work, but it can be tedious to find the excact right parameter, so a optimization library is recommended.
plt.plot(train_losses, label="Train")
plt.plot(validation_losses, label="Validation")
#plt.yscale('log')
plt.legend()
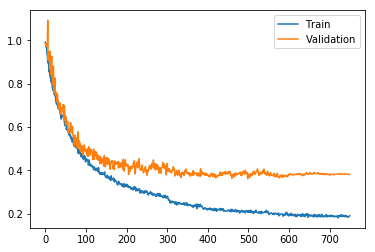
Evaluating the performance
The model is switched into evaluation mode and some statistics are calculated in the form of root mean square error (RMSE).
model.eval() #Swith to evaluation mode, where dropout is switched off #y_pred_train = model(X_train_t) y_pred_validation = model(X_validation_t) #y_pred_test = model(X_test)
torch.mean(( y_validation_t - y_pred_validation )**2).item()
0.38138607144355774
Let’s also vectorize the train and test sets and see how they perform.
X_train_t = smivec.transform(X_train, canonical=False) X_train_t = torch.tensor(X_train_t, device=device).float() y_train_t = torch.tensor(y_train, device=device).float() X_test_t = smivec.transform(X_test, canonical=False) X_test_t = torch.tensor(X_test_t, device=device).float() y_test_t = torch.tensor(y_test, device=device).float()
y_pred_train = model(X_train_t)
y_pred_test = model(X_test_t)
train_rmse = torch.mean(( y_train_t - y_pred_train )**2).item()
test_rmse = torch.mean(( y_test_t - y_pred_test )**2).item()
print("Train RMSE: %0.3F\tTest RMSE: %0.3F"%(train_rmse, test_rmse))
Train RMSE: 0.162 Test RMSE: 0.374
A visual plot of the predicted versus real values can also help estimate the goodnes of the fit.
plt.scatter(np.array(y_pred_train.tolist()).flatten(), np.array(y_train_t.tolist()).flatten(), alpha=0.1) plt.scatter(np.array(y_pred_validation.tolist()).flatten(), np.array(y_validation_t.tolist()).flatten(), alpha=0.5) plt.plot([-1.5, 1.5], [-1.5,1.5], c="b")
[]

Compared to the fingerprint feed forward network, this model seems to be slightly worse. Deep learning usually require a lot of data, and this dataset may not cut the bill in size. Alternative more tuning is needed to get the right hyperparameters for the networks, such as learning rate, dropout, networksize, etc. But reading in SMILES can be used in a lot of other interesting architectures, and this model illustrates the foundation for reading-in molecules in SMILES format for a PyTorch based artificial neural network.
Hi Esben,
I have a set of 45 active and 955 inactive small molecule fragments (6-21 heavy atoms), have tried many fingerprint representations but all the resulting MLPs give always nan probability. One possible reason is that small-molecule fragments are too small to be described by fingerprints. Even worse, my goal is to use the fragments as a training set, create a classifier, and subsequently screen large chemical libraries of normal-sized molecules. Do you think that SMILES representation and LSTM networks would be a better alternative for this purpose?
Hi Thomas,
If you MLPs give nans, there’s usually a weight “blowup” or something wrong in the construction of the network. Does it give nans after training, or also before any training has been conducted just with the initialized weights?
I’m not sure how SMILES models would work with your dataset, I’ve not worked with so small fragments before or with a similar situation so I’ll just answer with what I think, not from experience. But the model could probably learn something from the fragments, but as you go outside the applicability domain with your larger molecules, it may need adjustments to the new domain, e.g. maybe bias-slope correction using a few known ligands of the large molecules. Usually the SMILES models need quite large datasets to be performant, but as you have smaller fragments the 1000 samples may be enough. I assume you will try dataaugmentation with SMILES enumeration? Let me know how it works out.
Just found this blog and is awesome. I already recommended to my coworkers 🙂
I’ve been working with LSTM models for a few months now. My goto strategy is to use ULMFit and the results are quite competitive with SOTA models.
Great to hear. What are you using for pretraining?
A general model trained with SMILES from ChEMBL. Using the fastai library makes training quite fast and easy to implement.
Nice!
Referring to:
class Net(nn.Module):
def __init__(self, dimensions, lstm_size, hidden_size, dropout_rate, out_size):
super(Net, self).__init__()
length = dims[0]
number_tokens = dims[1]
What are the uses of defining length and number_tokens in the class?
Well, probably a leftover from reusing some code. The number_tokens is used to define the input size for the LSTM cells, but the length is not needed for this network. Also it should read dimensions (as in the init call, not dims), so the code should more look like this:
class Net(nn.Module):
def __init__(self, dimensions, lstm_size, hidden_size, dropout_rate, out_size):
super(Net, self).__init__()
#length = dimensions[0]
number_tokens = dimensions[1]
And later
model = Net(smivec.dims, lstm_size, hidden_size, dropout_rate, output_size)
Hi, all the posts are really nice here, I get to know a lot of things.
I have couple of doubts , 1) I see in tutorials to use torch.no_grad() in the validation time, why it isn’t use here?
2) why there is model.train() after the calculation of validation loss
3) compare to the other post using fingerprint to train feed forward neural network, here “lr_scheduler.step(validation_loss)” is used, what is it doing?
Thank you so much for the blog.
Hi M,
Thanks for your interest in my blogposts. @1, yes, that is probably best to run the inference with no_grad(), but as it’s a small network and not a lot of samples, so I don’t think it would make a huge difference. @2. The validation loss is calculated after putting the model in eval() mode, which switches off dropout as example, model.train() put it back into training mode. @3 the step scheduler lowers the learning rate when the validation_loss stops falling, it’s configured in a previous jupyter cell. It is needed for full convergence here.
Happy Hacking
Esben